Olá,
Se vcs ainda estão vendo novos URLs indexados no site, eu sugiro uma regra de firewall no Cloudflare que pode ajudar a conter o problema e também a investigar sua origem.
Basicamente eu criei uma regra baseada em URLs que apresenta um Captcha para qualquer visitante (inclusive o Googlebot) que tentar uma das URLs que não estejam no sitemap do site, ou não seja um arquivo de imagem ou css/js etc.
No caso do site do @ferschiavinato, vi que é um site pequeno, portanto será fácil e possível implementar. Se o site for muito grande, tiver muitas URLs, pode não ser possível, já que cada regra de firewall no Cloudflare é limitada em tamanho a no máximo 4kb. Tem que testar.
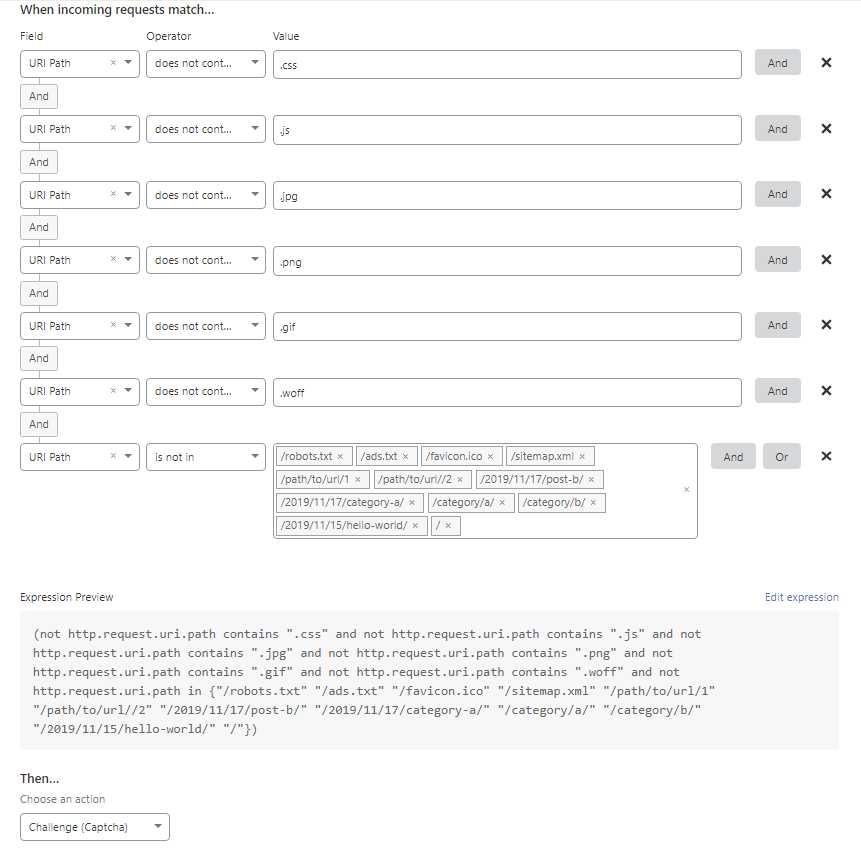
Num site de testes com somente 2 posts, Post A e Post B, e duas categorias, também A e B, além do inescapável Hello, World!, teríamos uma regra de firewall assim:
https://snipboard.io/6MVD3i.jpg
As primeiras regras listam as extensões de arquivos CSS, JS, de imagem etc. No plano gratuito do CF não dá para usar uma expressão regular, por isso tem que listar uma por uma.
Depois uma regra que lista os URLs (na verdade, somente o “path”, para a regra ficar mais curta) que não devem ser bloqueados, como os dos posts e categorias, a “/” para representar a página inicial, e alguns arquivos especiais como ads.txt, robots.txt, sitemap.xml etc. Não é necessário excluir arquivos solicitados fora do domínio, como fontes do Google, etc, pois o firewall não atinge essas solicitações.
E por fim a ação Challenge (Captcha), que apresenta um bloqueio com erro 503 para os bots e uma página de captcha para os visitantes.
Ao implementar essa solução, visite seu site com a ferramenta do desenvolvedor aberta (F12 no Chrome) e repare se tem alguma coisa sendo bloqueada, ajustando a regra conforme o exemplo acima. Ou rastreie o site usando uma ferramenta do tipo Screaming Frog para ver se tem algo que está sendo barrado e não devia.
A partir daí, o Googlebot irá ser barrado toda vez que requisitar os URLs que não foram excluídos pela regra do firewall, inclusive os 404 que não têm nada a ver com o hack japonês. Em vez de aparecerem na lista de 404 no Google Search Console, esses URLs vão ser listados como erros de rastreamento (crawl anomaly). É importante monitorar diariamente o GSC, mas esse tipo de erro não gera penalidade quando os URLs não foram enviados ao GSC via sitemap.
Caso o GSC acuse que esses URLs bloqueados foram submetidos a ele, então há uma grande chance de (1) os hackers terem acesso a sua conta no Google (nesse caso, troque as senhas, implemente 2FA etc), ou (2) os hackers estarem gerando um sitemap invisível que só é gerado quando o próprio Googlebot navega no site, o que daria uma ótima pista para investigar na sua instalação do WordPress que tipo de plugin poderia estar sendo utilizado para tanto.
Essa regra não tem o propósito (nem o poder mágico) de eliminar o problema em si (a infecção do site por malware), mas sim de impedir que o hack funcione, barrando o Googlebot de rastrear os URLs, e consequentemente de indexá-los. Em vez de tentar enxugar gelo bloqueando pelo robots.txt os URLs só depois que eles já estão indexados pelo Google (e outros buscadores), essa regra impede que o Google sequer acesse os URLs.
Para eliminar o hack, tem que seguir os passos listados em https://codex.wordpress.org/pt-br:Site_Invadido, com especial atenção para a troca de senhas, troca dos “sais” do WP, e adoção do 2FA. (Imagino que já tenham feito isso, mas não custa lembrar!)
{kind=link}